Save input file
Allows you to save your input file as a metadata, for future use as explained in the next steps.
The parameters are :
Allows to duplicate the incoming message, and inject it into another channel.
The parameters are :
When the incoming message must be duplicated in the process of the original message. If Duplicating the message later, the message will not be duplicated if the message fails some validation. |
|
The gateways to which the duplicated message will be sent. |
|
The strategy that will be used to transfer the user metadata to the new message created in the connected gateways. |
Note: This extra processing is not executed while running a test case.
Allows you to extract your input file from a zip. It also allows you to save other files of the zip to be reused, in the next steps.
As an example, suppose that your channel is designed to process xml orders. However, instead of directly receiving the xml order from your partner, you receive a zip file that containing the expected file order.xml, and also a file order.pdf. You can just extract your order.xml file by using this extra processing with the pattern 'order.xml'. If you need it for later use, you can also save the pdf file for future use (reuse in your transformation, reinclude it in archive in message out, ...)
The parameters are :
Pattern (regular expression) for the file name in the zip of the file that will become your input message. First match is used. |
|
Allows you to save other files of the zip for future use. For every file that you want to save, you have to specify the pattern of the file name in the zip and the name of the metadata in which you want to save the content. If one pattern matches multiple files, it is possible to save them all if you guarantee to generate a different metadata name for each. This can be achieved by using the capturing groups of the regex in the metadata names. Ex: if your pattern is (.*\.csv) and your metadata name is attachment-$1, processing with files file1.csv and file2.csv will result in two metadata as follows attachment-file1.csv and attachment-file2.csv . |
Allows you to extract your input file from a pdf. It also allows you to save other files of the pdf to be reused in the next steps.
As an example, suppose that your channel is designed to process xml orders. But instead of directly receiving the xml order from your partner, you receive a pdf file, with your xml order included as a pdf attachment. You can extract your order.xml file by using this extra processing with the pattern 'order.xml'.
The parameters are :
Pattern (regular expression) for the file name in the pdf of the file that will become your input message. First match is used. |
|
Password, if any, to open the pdf file. |
|
Allows you to save other files of the pdf for future use. For every file that you want to save, you have to specify the pattern of the name of the pdf attachment (first match) and the name of the metadata in which you want to save the content. |
Allows you to extract your input file from a MIME envelop. It also allows you to save other files of the MIME envelop to be reused, in the next steps.
The parameters are :
Pattern (regular expression) for the file name in the MIME of the file that will become your input message. First match is used. |
|
Allows you to save other attachments of the MIME envelop for future use. For every file that you want to save, you have to specify the pattern of the name of the attachment (first match), and the name of the metadata in which you want to save the content. |
|
The alias of the key (in the keystore of your environment) that will be used to check the signature. |
|
Enables or disables the check of the signature. |
Allows to decrypt a file encrypted using PGP.
PGP supports message authentication and integrity checking. The latter is used to detect whether a message has been altered since it was completed (the message integrity property) and the former to determine whether it was actually sent by the person or entity claimed to be the sender (a digital signature). Because the content is encrypted, any changes in the message will result in failure of the decryption with the appropriate key. The sender uses PGP to create a digital signature for the message with either the RSA or DSA algorithms. To do so, PGP computes a hash (also called a message digest) from the plaintext and then creates the digital signature from that hash using the sender's private key.
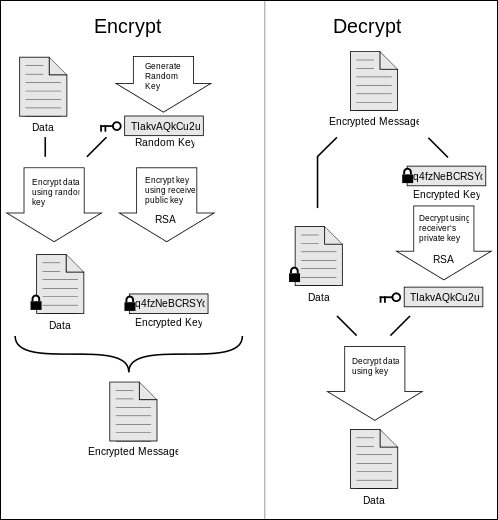
The parameters are :
Allows you to validate the Xml Signature.
The parameters are :
Allows you to make a global search and apply regular-expression replacements on your input file, before it is analyzed.
You can define more than one pair of regular-expressions to find & replace pattern.
The parameters are :
Allows you to remove ASCII Control characters from input file.
Characters removed are : [x00-x09]|[x0B-x0C]|[x0E-x0F]|[x10-x1F]|x7F
This extra processing analyses the incoming message, and associates the following metadata to it:
The type of document, like 'ORDERS', 'INVOIC', 'DESADV', ... |
|
The format of the message, like 'EDIFACT', 'X12', 'IDOC', ... |
|
The version of the message format. For example, for EDIFACT, the version can be '96A', '01A', ... |
|
The identification of the sender of the message. |
|
The identification of the receiver of the message. |
|
The intergration of the five previous fields, separated by '_'. The goal of this field is to simplify the writing of routing rules, or of keys of messages, that want to use all of the above fields. |
The metadata will typically be used by a following routing. As an example, suppose that you receive orders in different formats with the same gateway. This extra processing can be used to identify the following formats: EDIFACT, X12, IDOC (xml or flat file), RND, VDA, cXML, UBL. This information can then be used to route the message to the correct message definition.
Parameters :
The XML is defined as followed :

Note: In Babelway, we're using the standard Java version of REGEX, and it's the same used all over the system.
This is another example on how to identify CSV file.
This is a sample of the CSV file
SenderID,ReceiverID,MessageKey,DocumentType , DocumentNumber , Date , Time, ItemNumber, ItemDescription, ItemQuantity, ItemPrice 8431598762018,2139854706451,1ae187a1-afe7-108e-9343-37971a38b936,InvoiceDocument,17052017,0205,01,Item Description 1,3,15.75 8431598762018,2139854706451,108e9343-e187-e933-71a3-187a1afe7108,InvoiceDocument,17052017,0205,02,Item Description 2,1,75 8431598762018,2139854706451,71a3187a-43e1-7a1a-ae18-97a57c17423a,InvoiceDocument,17052017,0205,03,Item Description 3,5,5.5 8431598762018,2139854706451,aae1848c-7618-a0c1-f941-37971a38b936,InvoiceDocument,17052017,0205,04,Item Description 4,7,17 8431598762018,2139854706451,0ca57c1f-c7ff-4952-c5af-12a0c1f941a3,InvoiceDocument,17052017,0205,05,Item Description 5,2,7
Below are the positions of the (Sender, Receiver, Type) that we will extract from the CSV and will use to create the Custom Identifier file.
The UniversalRouterSender will be extracted from the second row, first column.
The UniversalRouterReceiver will be extracted from the second row, second column.
The Type will search for "InvoiceDocument" in the CSV file.
The XML is defined as followed:

Below is a print screen from the "contextOut.xml" file from the CSV processed message showing the extracted information saved in the universal router metadatas.

Note: To be able to get the value from an XML file containing a namespace, you will need to use the *: for the prefix in the XML path when using the xpath for the Custom Identifier file.
For example, below is the path to use if you want to get the value in the field "cbc:ID" from the below input message and save it under "Type" for the custom identifier file.

The path is /*:Invoice/*:ID

Note: This extra processing is not executed while running a test case.
Allows to save a human readable PDF version as a metadata, for future use in the next steps. This is only available for Edifact and X12 messages.
The parameters are :
Calls upon Trustweaver to process your message. See http://www.trustweaver.com for more informations.
The parameters are :
The Trustweaver environment that is targeted by the process. |
|
The alias of the key (in the keystore of your environment) that will be used to authenticate to Trustweaver. |
|
The TrustWeaver code of the country for which the Trustweaver process will be done. |
|
The TrustWeaver format of the document for which the Trustweaver process will be done. |
|
The TrustWeaver format of the signature for which the Trustweaver process will be done. |
|
The XPath that targets the tax id in the xml payload and that will be used for the Trustweaver process. |
|
A pattern designating the validation outcomes that are accepted. |
|
If the TrustWeaver process fails, the message will be put in error. |
Note:
- For a complete list for the Trustweaver system metadata and more information about the system metadata check this link System Metadata
- This extra processing is not executed while running a test case.
Applies an xslt to correct your message. It is applied on the internal xml representation of the message (after the message has been analysed and converted).
Be aware that the message resulting from your transformation must conform with the message definition (tree structure).
The parameters are :
Allows you to extract any information in the input message to be able to view it directly in the monitor page.
As an example, suppose that you want to extract some information from the input message to be able to view it directly in the monitor page.
First, create the "Document type" you want to use from "Admin / Envirnment settings / Document types"
Based on the information you want to store, you will need to create its corresponding document type, as shown below.
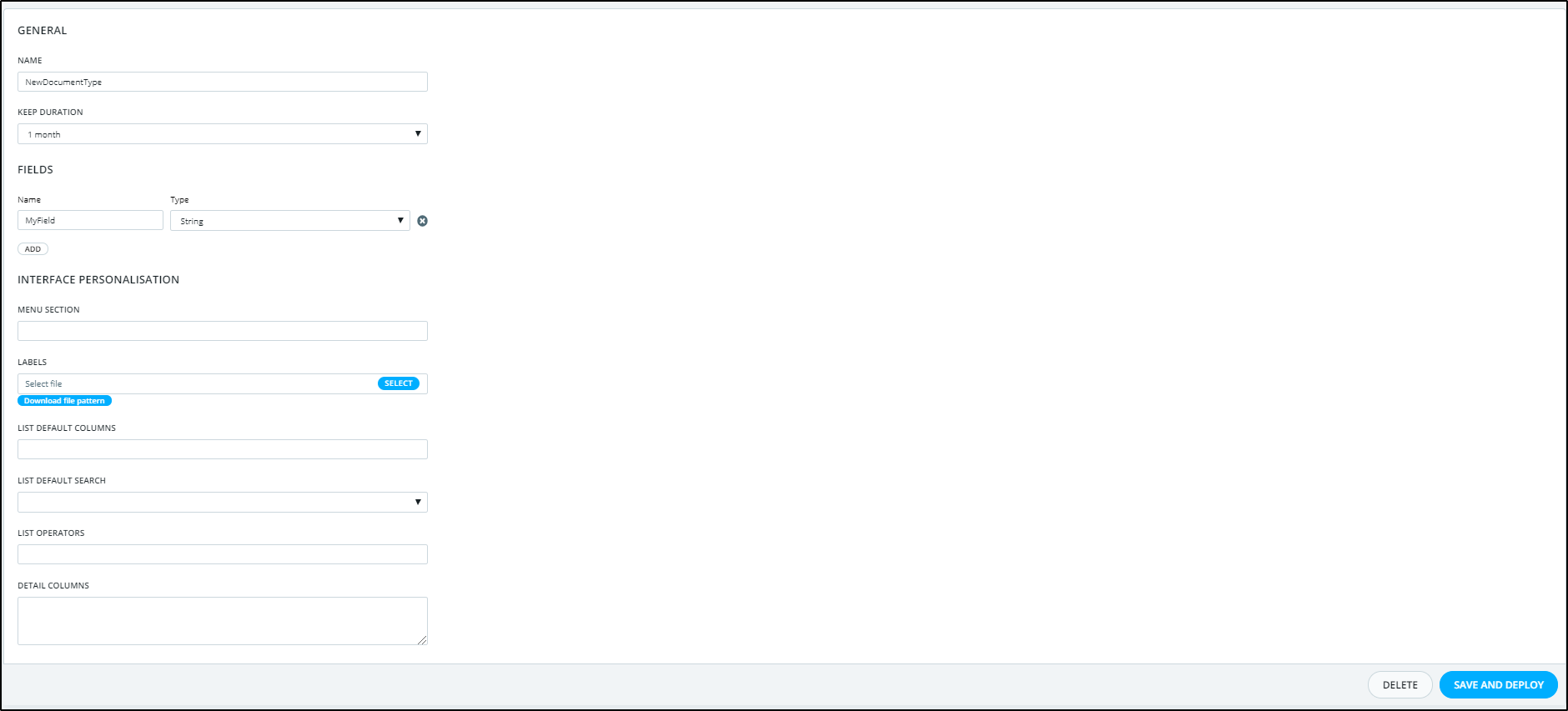
Note: For more information about the Document types you can check this link Document types.
Then, create this extra processing in the "Message In" and after that click on "Edit" to map the fields you want to extract, as shown below.
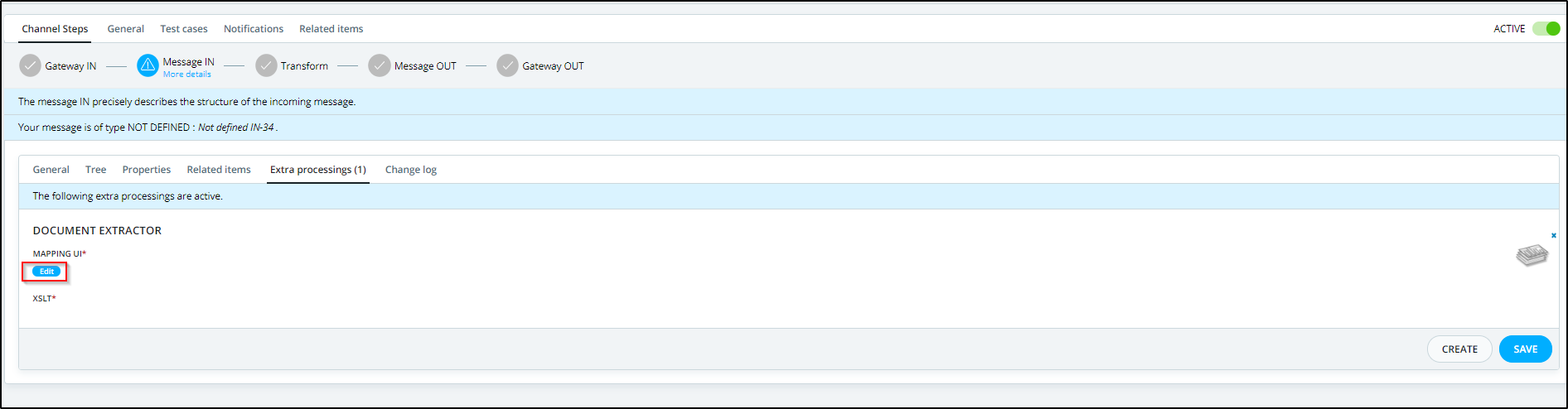
After that, begin mapping the fields from the input message you want to extract to the fields in this document type, as shown below.
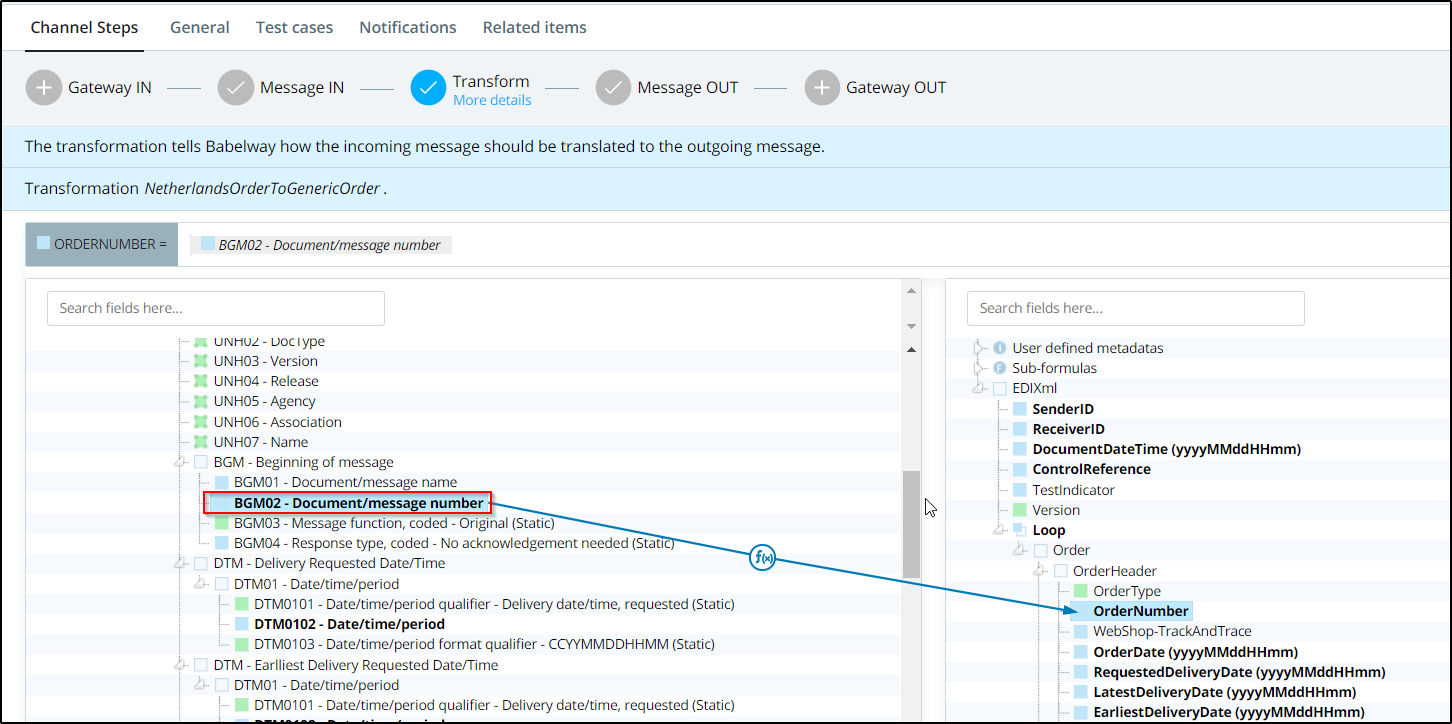
To be able to view the extracted information, go to monitoring and then based on the "name of the document you used" ("orders" in this case), click on it to view the extracted information, as shown below.
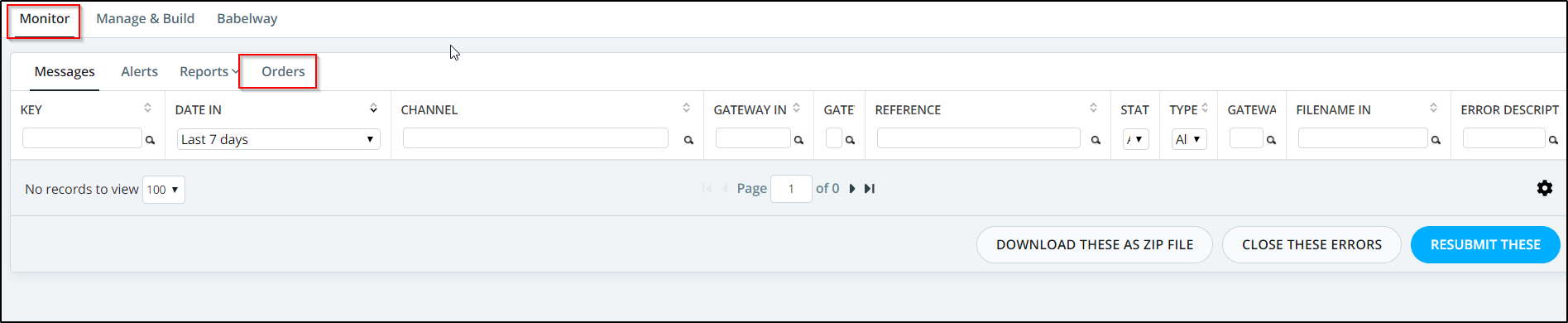
Note: In order for the new document type to be displayed in the Monitoring page after using it in it's corresponding channel or channels you will need to deploy your environment in order to push this changes to production and the new document will be displayed in the Monitoring page, as shown below.

This extra-processing allows to define criteria to automatically close an error that occurs during the message definition IN step.
The parameters are :
|
The patterns that will be tested against the error message. If the error message matches at least one of the patterns, the status of the message will automatically be set to Error(closed). |
This extra processing allows you to identify and reject incoming duplicate messages.
When a message comes in, it is identified by a key (it can be the file name, a hash of the message, an xpath or regex extract of the message, or a metadata value). This key is then checked against previously recorded keys in a dedicated lookup table. If the message matches an existing entry, it is set in error.
Mode |
Indicates the way to identify the message's unicity: MD5 hash, 256 hash, xpath or regex extraction, file name, or metadata value. |
| Create new lookup table | Check this box to indicate that you'd like the system to create a new lookup table rather than use the one in the field (lookup table) |
| Lookup table |
Lookup table which will be collecting your message identifiers, the babelway message key, and the date at which the message came in. The table requires the exact following structure:
You may complete the lookup table with any additional information but any change to these first three columns will break the functionality. |
| Pattern | (optional) In the regex mode, the pattern is the regular expression to extract the unique identifier. Note that if the resulting text exceeds 200 chars then its sha256 hash is saved instead. |
| Xpath | (optional) In the xpath mode, this is the expression to extract the unique identifier. Note that if the resulting text exceeds 200 chars then its sha256 hash is saved instead. |
| Metadata name | (optional) In the metadata mode, this is the name of the metadata you wish to use to uniquely identify your message. Note that if the resulting text exceeds 200 chars then its sha256 hash is saved instead. |

Allows you to search the input message by using one or more regex in the Find field(s) then the user defined metadata will be created using the name provided in the MetadataName and its value will be generated from the Value field when the provided pattern in the Find field matches the requested value in the input message.
You can define more than one pair of regular-expressions to find & generate metadata.
The parameters are :
The list of parameters (Find:Pattern, Value:String, MetadataName:String) which the extra-processing takes. For every of these elements, the extra-processing will evaluate the pattern and, if it matches, evaluates the value, and sets it as a user metadata with the requested name. First match is used. |